How the Merge Join Works in SQL Server
SQL Server offers several join algorithms to combine data from multiple tables. The merge join is one of the most powerful and efficient join types when used correctly.
What is a Merge Join?
A merge join is a join algorithm that combines two sorted input data streams based on a joining condition. Unlike other join types, merge joins require both input streams to be sorted on the join columns.
Before a merge join, both input streams must be sorted by the joining columns. Generally, this can be achieved by indexing the relevant columns. Let’s consider an example.
Here we have two simple tables: Students and Marks. The Students table contains two columns, Id and Name, while the Marks table has two columns, StudentId and Marks. Our goal is to join these two tables by the fields Students.Id and Marks.StudentId.
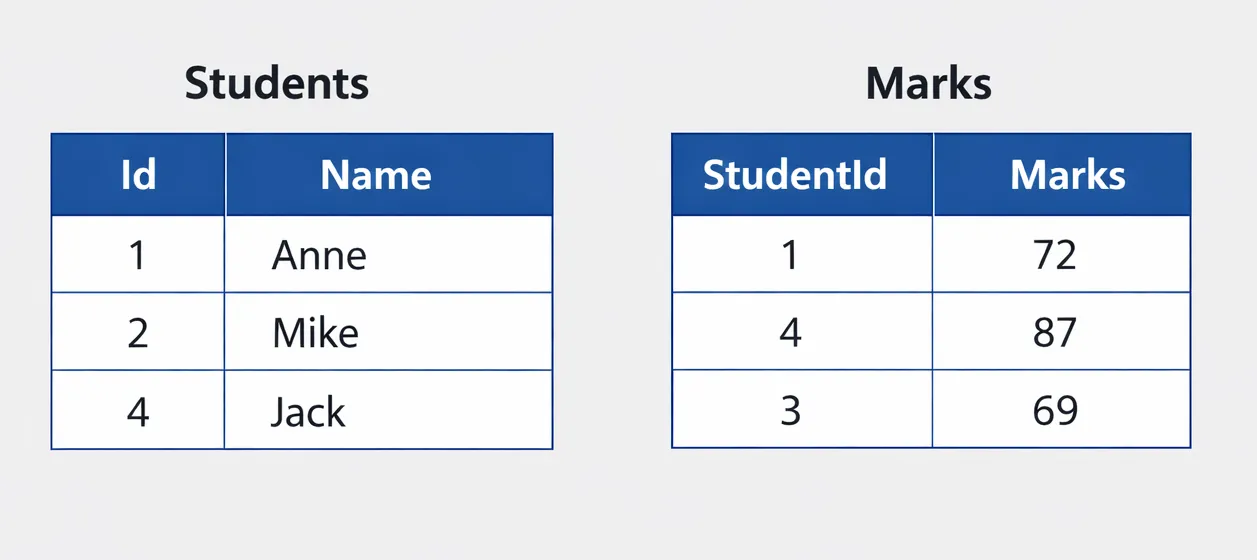
As you can see, in the Students table, the Id column is sorted. However, in the Marks table the StudentId column is not sorted (1,2,4 vs 1,4,3).
In order for us to perform a merge join, first we have to sort the joining column of the Marks table.

Now we have sorted the Marks table based on the StudentId field.
Next, SQL Server starts the process at the top of both tables. SQL Server compares the current rows of the tables.
- If the current rows match (Students.Id = Marks.StudentId), then the row can be merged.
- If the left < right (Students.Id < Marks.StudentId), then the left side is moved forward and checked again.
- If the left > right (Students.Id > Marks.StudentId), then the right side is moved forward and checked again.
This process will run until one table ends.
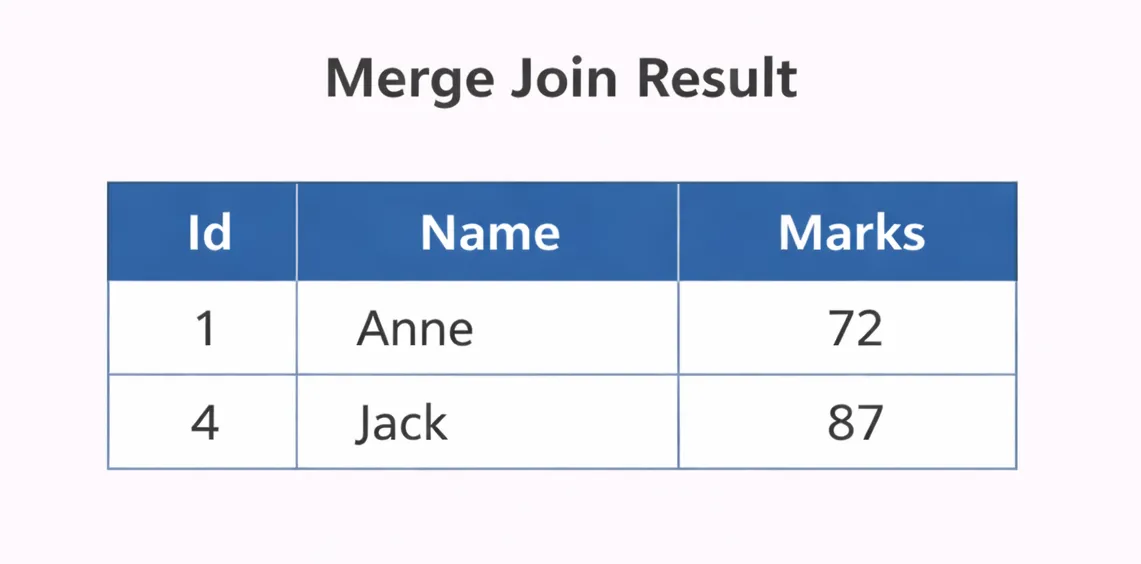
For the example above:
- Compare 1 vs 1 -> match
- Compare 2 vs 3 -> no match; the left side is moved forward
- Compare 4 vs 3 -> no match; the right side is moved forward
- Compare 4 vs 4 -> match
Final result:
Best use cases for merge join
The merge join is best suited for tables with a large number of records, sorted inputs, and an equality join condition with no (or minimal) duplicates. The rows are compared one by one, so there is no need to load the entire tables at once.
Why is merge join so fast?
Merge join has an O(n + m) complexity (n = number of rows in table A and m = number of rows in table B), which implies that the total work = scan A once + scan B once. In a merge join, the algorithm doesn’t loop back (it never restarts from the beginning); it flows only forward. So each row is touched only once. This is considerably faster compared to an algorithm that loops back, which can have a complexity of O(n x m).
Example: If table A has 2000 rows and table B has 3000 rows:
- O(n + m) = 2000 + 3000 = 5000 operations
- O(n x m) = 2000 x 3000 = 6000000 operations
All this depends on the prerequisite that the tables are sorted by the joining column.
What if tables are not sorted by the joining column?
If the tables are not sorted, SQL Server will go for a different kind of join mechanism (e.g., a hash join or a nested loop). Otherwise, SQL Server will decide to sort the tables first and then go for a merge join. SQL Server is smart enough to generate multiple possible plans and then pick the least costly one. For this, SQL Server uses table statistics (e.g., row count, distribution), index metadata, etc.
The complexity of sorting table A with n rows is O(n log n). So if both tables are unsorted, the sorting cost = O(n log n + m log m) (which is equal to total sort + merge cost, and the merge cost is comparatively very small compared to the sorting cost).
Limitations of merge join
Merge join only works best when the join condition is: A.key = B.key. In such a case, the process is linear. If a match is found, it sends the row to the output.
But if the join condition is a non-equality (e.g., A.key < B, A.key BETWEEN B.x AND B.y), then a single value can be matched with many values. This calls for rechecking multiple rows and backtracking. Therefore, the O(m + n) complexity disappears here. A similar thing happens when there are duplicates in the tables.
Let’s assume the joining column of table A has (5,5) and that table B has (5,5,5). In that case, SQL Server stores the matching rows from one side (usually the right side) as a buffer. Then it matches them with all the rows on the other side.
- All the B rows with value 5 are stored. Each A row with value 5 will be matched with all buffered B rows.
- If A has 2 rows with value 5 and B has 3 rows with value 5, then output = 2 x 3 = 6 rows.
This requires memory because there is a need to store all the matching rows (buffer). Also, the same rows are reused multiple times, so it’s not “move forward once” anymore.
The same happens with inequalities. If the joining condition is A.id < B.id, each A row will match with a range of B rows. So SQL Server will buffer a part of B and reuse it across multiple A rows. This has more comparisons, therefore it takes a lot more memory.
These inequality and duplicate-key situations are called Many-to-Many Merge Joins.
If expressions are used in the joining condition (e.g., ON YEAR(o.OrderDate) = YEAR(c.JoinDate)), it can break index usage and force a sort.
Optimization of merge join
Merge join is already efficient. The way to optimize is to remove the things that force extra work (sorting, buffering, scanning).